
vii. Pillar Five: Scaling AI
Pillar Five: Scaling AI
The Economist writer we cited in this white paper’s Background section concluded by asserting that “the most significant benefits from new forms of AI will come when firms entirely reorganize themselves around the new technology,” while cautioning that “gathering data is tiresome and running the best models expensive,” and pointing out that 40% of American small businesses report being uninterested in AI tools.
In time, though, most organizations will turn their attention from future readiness and establishing themselves with AI to focusing instead on scaling (and sustaining) their investment in AI and the data platform upon which it depends. Put another way, one-time consolidation and readiness of data combined with a few AI-driven workloads does not a future-ready organization make.
First, organizations must tune their technical capabilities to support the scaling of AI. Some of this will be directly relevant to AI itself, for example, employing AI Operations (AIOps - including Machine Learning Operations (MLOps) - to build, deploy, monitor, and maintain production models, incorporating rapid advances in the tech to your enterprise machine learning platform where you’ll land your workloads and operate them in your daily business.
First, organizations must tune their technical capabilities to support the scaling of AI. Some of this will be directly relevant to AI itself, for example, employing AI Operations (AIOps - including Machine Learning Operations (MLOps) - to build, deploy, monitor, and maintain production models, incorporating rapid advances in the tech to your enterprise machine learning platform where you’ll land your workloads and operate them in your daily business.
Second, there are human Digital Literacy considerations that should be thought about as you progress AI across the organization. There is a significant element of people-centric scaling and change management required here. In other words, the baking of AI into the way people work.
We’ll explore these and other dimensions in the pages that follow.
AI Operations (AIOps)
When we speak of AI Operations (AIOps), we’re talking about the patterns, best practices, and enabling tools used to develop, tune, test, incrementally improve, and productionize these types of AI workloads and the models themselves in a scalable way, automating where possible to achieve efficiencies and reduce human error. In this way, AIOps is itself a sub-discipline within DevOps, and mirrors many of the patterns (e.g., CI/CD), best practices (e.g., automate where possible), and enabling tools (e.g., Azure DevOps) found in “traditional” DevOps.
Just as AIOps is a sub-discipline of DevOps, so too is Machine Learning Operations (MLOps) a component of AIOps. It’s confusing, so let’s set the record straight.
It's easy enough to use the terms “Artificial Intelligence” (AI) and “Machine Learning” (ML) interchangeably, so let’s clearly define the difference.
AI is a broad and evolving field wherein the technology mimics, and in some cases surpasses, the cognitive abilities of humans. This broad category encompasses everything from “if this, then that” scenarios where the seeming “intelligence” is the product of pre-determined decision trees and patterns that humans have themselves created, all the way to “generative AI” where the technology is able to generate bespoke answers to questions, images, insights, and other responses based on its index of accumulated knowledge.
ML is a sub-discipline within the broad category of AI, wherein the machine “learns” and refines its own capabilities based on the information and feedback it encounters, and based on the tuning that ML engineers apply over time.
Implementing and maturing AIOps will, for many organizations, involve a simultaneous maturing of their DevOps capabilities to be relevant in the age of AI, as well as maturing their MLOps to support their machine learning models.
Data Governance
We briefly discussed Data Governance as part of the Ecosystem Architecture pillar’s Core Platform Services dimension, particularly insofar as establishing baseline or minimum viable product data governance as an essential part of building and maturing an organization’s cloud landing zone.
Data Governance is so important to a future-ready enterprise AI strategy for several reasons:
AI strategy elevates the centrality of the modern data platform in an organization’s technology ecosystem, bringing data out of the shadows such that we finally - at long last - replace the “security by obscurity” approach that has loomed in IT for many years, with a deliberate and rigorous approach to data governance;
Earlier we said that “data is the essential fuel without which AI models cannot be trained nor have the capacity to act,” so, simply, data governance is essential to the care and safeguarding of AI’s most important asset, and to mitigating the risks of AI hallucination (incorrect or misleading responses), and the RAI topics of reliability and safety, privacy and security, inclusivity, transparency, and accountability gone awry;
Finally, as we have said, the data distribution capabilities that we’ve instituted as part of our AI strategy will also be used in analytical workloads, search, integration with third parties, and more; strong data governance improves the outputs of these classes of workloads, as well.
Microsoft continues to invest heavily in its Purview capability to provide for data governance, security, quality, lineage, compliance, etc. across the data estate. In accordance with the time honored principle of “following the money,” we recommend that implementation of Purview be an early-stage milestone in nearly every organization’s AI strategy, and that your Purview implementation be matured and kept current with the evolution of the organization’s data estate (and the product’s latest capabilities) over time.
We’re also still early days when it comes to anything like unified data security and role-based access controls (RBAC) across a large organization, so we both expect and are hopeful that the next couple of years will see increased convergence around a data security model that is established at the source and hydrated throughout our ecosystem. This is important so that information security teams can be confident that a nugget of data to which a user would never have access in the context of its source application, does not somehow pop up for that user in an AI or analytical scenario downstream. We’ll cover these risks from another perspective in the Technical Debt dimension.
Microsoft promises these sorts of robust conditional access capabilities in Fabric, but we suggest a combination of caution and - of course - rigorous information security best practices as we see how this plays out.
Robust data governance should, at a minimum, be instituted for all data residing within the Core Business Systems and Data Distribution Neighborhoods in your cloud ecosystem. We also recommend serious thought be given to establishing data governance of data residing in the Tier 2 or “business important” applications discussed in the Ecosystem Architecture pillar.
Technical Debt
Gartner forecasted a 6.8% rise in global IT spending for 2024. Around the world and across industries, technology leaders struggle to bend their cost curve even as new investments in artificial intelligence and the data platform technologies required to power it become more pressing.
A Forrester Total Economic Impact Study in July 2024, also mentions technical debt as a risk associated with shadow IT and unauthorized software use. Before adopting Power Platform, organizations often face challenges with employees building their own solutions in tools like SharePoint and Excel, which can lead to technical debt. This debt arises because these makeshift solutions can create dependencies on unmaintained tools and processes, increasing risks related to security, compliance, and overall system reliability. The use of unauthorized software also complicates the governance and management of IT resources, further exacerbating technical debt within the organization.
Indeed, technical debt not only incinerates IT budgets and distracts from the hard work that organizations must undertake to modernize for the age of AI, but, more insidiously, AI itself exposes organizations to immense risk due to the technical debt found in their existing application estates.
Think back to the example from the Business Applications dimension…

Figure 28: The above diagram shows (icons noted in blue) an assortment of workloads common across many organizations.
These workloads have grown over time as point solutions implemented largely in isolation of one another. Their specific data storage technologies differ between organizations, but we’ve used a combination of Excel, SAP, proprietary databases, SharePoint lists, MySQL, and SQL Server to provide a representative sample.
Now, in nearly every organization we’ve worked with, individual applications in their fragmented collection of point solutions require significant amounts of common data. Personnel data offers a great example, because each workload shown above requires some degree of data or knowledge about the people working there. So, IT organizations build “spaghetti web” point-to-point integrations between data stores using a variety of tools including Power Automate, scattershot use of actual integration tools (event, logic, or batch integration), Excel, and even what we used to jokingly call “sneaker net”, in other words, manually moving data from one system to the next via physical media.
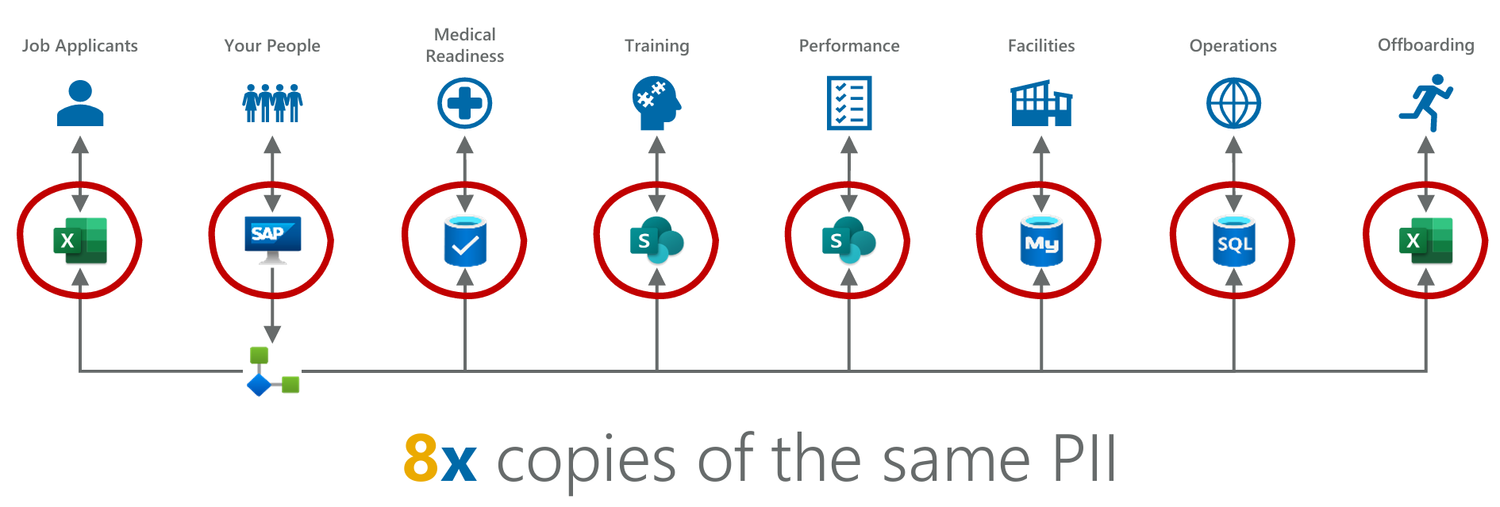
Figure 29: Working around technical debt limitations can often result in copying data multiple times from one location to another, multiplying data security risk and creating significant risk.
This copying of data - scratch that, this making copies of copies of data - often results in a catastrophic proliferation of (among other things) personally identifiable information (PII). Indeed, our scenario above has resulted in 8x copies of the same PII.
The phenomenon is even more insidious for organizations with large portfolios of “SharePoint apps” or Power Apps built atop SharePoint lists as their data source, overengineered workarounds to avoid the cost of properly licensing Power Platform. The diagram below replaces all of the data sources in the previous architecture with SharePoint, which may or may not be as ubiquitous in your organization but, let us tell you, it is in many.
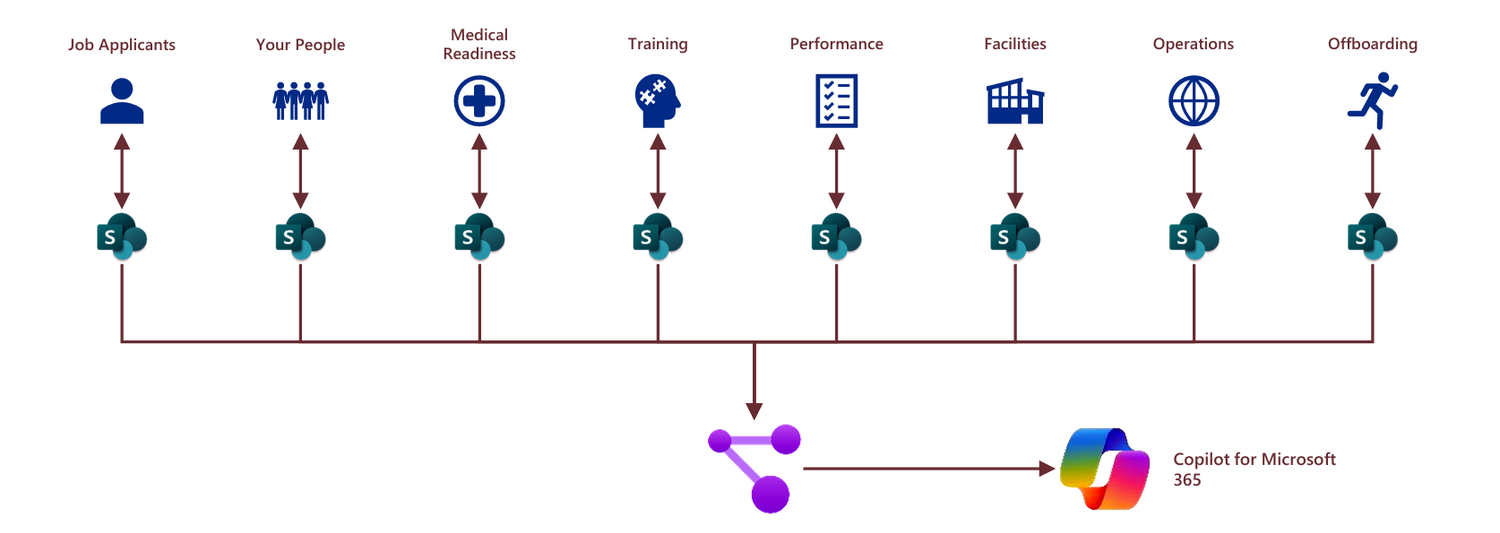
Figure 30: The diagram above replaces Excel, SAP, proprietary data storage technologies, MySQL, and SQL Server with SharePoint lists as the application data stores.
You see, the data kept in SharePoint is part of the Microsoft Graph, which itself hydrates Copilot for Microsoft 365 with your organization’s data. Those 8x copies of unsecured PII data have now been handed over to AI to craft generative responses for your users. Oh my.
To be clear, this is not a shortcoming of the technology. This is a shortcoming of poor architectural and security practices -fundamental misuses of the technology - that have created these security risks.
These are but examples of how technical debt hinders and creates significant risk when combined with artificial intelligence. Scaling AI requires these legacy technical debts to be retired to create budgetary space for new investments and to mitigate the risk that data from legacy, unsecured applications will improperly leak into your AI workloads.
Monitoring and Metrics
Scaling AI is far from a purely technical endeavor. It’s intuitive, in fact, to assume that long-term execution of strategy requires Monitoring and Metrics of the strategy’s efficacy in producing business results. Well-rounded monitoring regimes should account for five key considerations:
Maturity and risk;
Adoption;
Content moderation;
Technical performance;
Return on investment.
We’re giving a bit away here in discussing maturity and risk at this stage of the paper. Skip ahead to the section presenting the AI Maturity Model to understand how to evaluate the organization’s readiness or maturity for AI, as well as how to identify dimensions that present risk to be mitigated.
Adoption concerns the rate at which users take up a particular AI capability, how consistently they engage with the capability, and whether they continue engaging with the capability over the long term. We favor “weekly active users” (WAU), i.e., the number of users that actively use a given workload (let’s say Microsoft 365 Copilot, for example) each week. Monthly active users (MAU) has been a favorite metric in previous waves of technology adoption, but we find MAU to be misleading in the case of AI because AI requires such a cultural shift; a user who only engages once or twice a month is not likely to adopt “born-in-AI” ways of working and is thus unlikely to make significant productivity gains thanks to AI.
We also recommend employing a “rings of release” method when releasing new capabilities, then monitoring the uptake amongst colleagues. This is standard fare in software deployments, but for the uninitiated, this approach groups users for whom the capability will be available into concentric rings, say a closed circle of technical users, then business early adopters, and an ever-widening pool of users until the capability has been released to all target users. Monitor for WAU (or daily active users, if it makes sense) in each ring, identify and remedy obstacles to adoption in the smaller rings, and avoid releasing more widely until you’re satisfied with adoption in the predecessor ring.
Content moderation is crucial when implementing an AI product to ensure a safe, respectful, and legally compliant environment for users. Effective moderation addresses potentially harmful content, such as hate speech, explicit material, and misinformation, thereby preserving user trust and upholding community standards. For instance, input moderation may involve filtering user-uploaded images to detect obscene content, while output moderation could include analyzing text generated by AI to prevent the dissemination of inappropriate language. Content moderation is situational depending on your business, customers and goals. For example, requiring high amounts of blocking of violent imagery will be vital in business SaaS applications, but more nuanced in gaming.
Azure AI offers robust content moderation features, such as image moderation, text moderation, and video moderation, capable of detecting offensive content across multiple formats. Benefits include real-time monitoring, scalability to handle large volumes of content, and compliance with various international standards. These capabilities enable organizations to protect their brand reputation, enhance user experience, and foster a safe community.
Monitoring the technical performance of AI products is a multifaceted task that encompasses various metrics and benchmarks to ensure the systems are functioning optimally. Key performance indicators such as model accuracy, precision, recall, and F1 score are critical in evaluating the effectiveness of machine learning models.
Additionally, assessing workloads involves examining throughput and resource utilization to ensure the system can handle the expected volume of data and tasks. Responsiveness and latency are also vital metrics; low latency and high responsiveness indicate a well-optimized system capable of real-time or near-real-time processing.
Tools like performance dashboards, log analysis, and automated monitoring systems provide continuous insights into these parameters. Regular performance testing and anomaly detection are essential practices to preemptively identify and address potential issues, thereby maintaining the robustness and efficiency of AI products.
Azure AI Studio allows you to evaluate single-turn or complex, multi-turn conversations where you ground the generative AI model in your specific data (RAG). You can also evaluate general single-turn question answering scenarios, where no context is used to ground your generative AI model (non-RAG).
We learned through organizations’ experience adopting Power Platform (an earlier Microsoft platform technology that entered the mainstream in the 2018-2019 timeframe) that many organizations crave Return on Investment (ROI) data for every minor workload that’s deployed. This made sense in previous eras of big, monolithic software applications like ERP or CRM, but requires a more balanced, nuanced approach for AI (and for Power Platform, though this is a story for another time). Organizations that truly transform themselves for the age of AI will infuse AI throughout many, many aspects of its work.
We therefor recommend that ROI be measured explicitly for major “anchor” workloads, and in the aggregate for more micro-workloads, in other words, an aggregate assessment of worker hours saved, or costs reduced across the workforce or department.
Digital Literacy
We’ll begin this final Digital Literacy dimension with a personal story from Andrew (one of this paper’s co-authors, for those readers who didn’t skip straight to the biographies at the end).
In late 2023, my wife, Ana (another of the paper’s co-authors), and I found ourselves sitting at a café in Melbourne, Australia, with most of the day left before we needed to catch a flight. My first instinct was to spend thirty minutes scouring the internet for things to do or see in Melbourne, an idea that I did not relish because I dislike being glued to my phone when in good company.
Ana suggested that they seek advice from Microsoft Copilot (which was, at the time, branded simply as “Bing”). I had not thought of this, but curiously explained the situation to Bing and clarified where we were, how much time we had before we needed to go to the airport, and what kinds of sights we like to see when visiting a city. Much to my delight, in about fifteen seconds Bing suggested an entire itinerary for the day including sights to see and places to eat and drink. The itinerary was even organized according to a logical walking path from the place in the city where we were then sitting.
This capability had been in my pocket for months, but so ingrained was the impulse towards self directed Googling that it had never occurred to me that AI-infused Bing could do the work for me so much faster. Off we went to explore Melbourne!
It is not enough that we put AI into our colleagues’ hands (or pockets), lest it stay there until some outside force compels them to give it a try.
To understand this predicament, let’s consider a 2023 study published by Boston Consulting Group (BCG) finding “that people mistrust generative AI in areas where it can contribute tremendous value and trust it too much where the technology isn’t competent.”
BCG goes on to enumerate the study’s key takeaways:
“Around 90% of participants improved their performance when using GenAI for creative ideation. People did best when they did not attempt to edit GPT-4’s output;
“When working on business problem solving, a task outside the tool’s current competence, many participants took GPT-4's misleading output at face value. Their performance was 23% worse than those who didn’t use the tool at all;
“Adopting generative AI is a massive change management effort. The job of the leader is to help people use the new technology in the right way, for the right tasks, and to continually adjust and adapt in the face of GenAI’s ever-expanding frontier.”
The change needed in most of your non-technical colleagues can be thusly understood as:
Knowledge: Colleagues must know that a particular AI capability exists, what it does, where to find it (hopefully embedded in workstreams with which they are already comfortable), and - in some cases - be persuaded as to its merits over doing things “the old-fashioned way;”
Understanding: Comfort breeds acceptance, so it is important that you help colleagues understand how one interacts with AI generally and a given workload specifically, which should include a healthy awareness of how to talk with AI, how to write an effective prompt, and an understanding that AI workloads thrive on better information (so, explain where you are in Melbourne, and what kinds of things you’d like to see);
Skepticism: In particular, colleagues should have some grounding in how to be an ethical user of AI, recognition of possible hallucination, incorrect responses, or bias in training data, and an appreciation for the notion that AI workloads sometimes get things wrong, too.
Remember, also, that the leadership teams in most organizations have themselves not been immersed in concepts such as the latest technical skills, basic knowledge of data concepts, data literacy, responsible AI, how to use and apply AI in general, etc. Your digital literacy efforts ought to therefor include elements designed explicitly for senior and executive leaders such that they can develop the knowledge required to be the best possible organizational leaders in the age of AI.
Developers, engineers, IT colleagues, and others involved with creating AI capability ought to go several steps further.
Workloads and their user experiences should be designed to be increasingly born in AI rather than a traditional app with AI bolted on. As discussed earlier, this is a transition that will both take a bit of time to play out yet is likely to happen in earnest.
Microsoft’s Project Sophia is already pushing boundaries that are likely to burst wide open as more and more architects and developers experiment, refine, and commercialize their born-in AI solutions.
Whilst this first transition to born-in-AI workloads takes shape, the developer-equivalent to my Bing-powered exploration of Melbourne is already underway. For just as developers will learn how to build workloads that harness AI for end users, they, too, will continue to learn how to fully harness AI to help them build the workloads itself. It is difficult to land on a believable statistic here, but immense volumes of new code are now being written by AI in the form of tools such as GitHub Copilot.
Meanwhile, Copilot for Power Apps and other Power Platform services are now creating significant pieces of the workloads themselves based on the Copilot’s chatting with developers and citizen developers alike.
The human-centric change required of IT professionals will thus be two-fold:
Learn to build workloads and user experiences that are born in AI; and
Use AI to build the workloads and user experiences themselves.
Navigate to your next chapter…